Project Description
The goal of my final project was to use kernel-based techniques to cluster text documents, in the form of articles published in the Really Simple Syndication (RSS) format, into conceptually similar groups (or clusters).
Background
The primary problem I attempted to address in my project is one of clustering, which is the unsupervised classification of patterns into groups (clusters)2. The problem of clustering has received attention in a number of domains and there are several well known methods of solving these problems. In this project, I was looking to implement a solution that did not rely on greedy or gradient descent type approaches that often fall short of finding global optima. In the end, I implemented a version of the technique described by Shi and Malik which treats the problem as a graph partitioning problem and aims at extracting a “global impression”3].
Theoretical Look at the Procedure
Below is a somewhat theoretical description of the steps in the clustering algorithm. A more detailed description, including proofs of all of the mathematical concepts can be found in [3]. The approach presented there rephrases the problem as a graph partitioning problem and introduces a new measure of disassociation, Normalized Cut (Ncut), for which the solution attempts to minimize. While minimizing normalized cut exactly remains an NP-complete, the authors show that an effective approximation reduces to solving a generalized eigensystem.
-
Each of N article taken from the RSS feeds is represented by a word vector xi containing a list of unique stemmed words from that article with common "stop" words removed. It is very common in kernel-based techniques to use an inter-sample weighting metric which represents the liklihood that the two elements belong in the same cluster. I have implemented my weighting metric based on a Bag of Word Kernel1]. The weight for word vectors xi and xj is computed as,
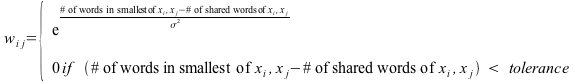
-
Solve the general eigensystem,
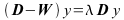
Where W is an NxN symmetrical matrix with W(i,j) = wij and D is an NxN diagonal matrix with di on its diagonal where,
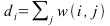
For a complete proof of why this finds an approximate global minimum of Ncut, see [3].
-
The second smallest eigenvector y1 can be used to partition the cluster into two sub-clusters, by assigning each vector xi to a cluster depending on whether the ith element of y1 is above or below the median.
-
Theoretically, it is possible to use the eigenector y2 to determine how best to partition further, but the approximation error from the real valued solution to the discrete valued accumulates with each eigenvector, so it is unreliable in practice.
A safer approach is to recursively run the algorithm subdividing each cluster independently until Ncut(A,B) exceeds a certain limit, where Ncut(A,B) is,
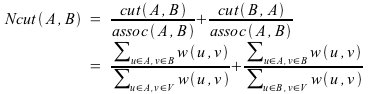
Implementation Sidenotes
As mentioned above and in [3], using eigenvectors other than the one that corresponds to the second smallest eigenvalue proved unreliable in my first implementation. It resulted in spurious mis-classification of individual articles. Examination of the eigenvectors revealed that elements that were relatively close to the median in the second smallest eigenvalue would often cross over in subsequent eigenvectors. So while it means a considerable hit to performance, my second attempt completely recalculates W, D and the corresponding eigenvalues. Each iteration does experience speedup, however, due to smaller cluster sizes.
At this point the system introduces some unfair weightings to shorter articles due to the fact that the absolute counts are used in the weighting metric.
Finally, I haven't had near enough time to test the system against real data. The only real data used in the demo below is a subset of my own RSS feeds. The other sets are generated trivial test data to ensure proper functionality.
The word extractor used is embarrassingly simple and could use a lot of improvement both in the tokenizing of words and in the filtering of common words.
References & Resources
- 1 De Bie T., Cristianini N., “Kernel methods for exploratory data analysis: a demonstration on text data”, in Proc. of the joint IAPR international workshops on Syntactical and Structural Pattern Recognition (SSPR 2004) and Statistical Pattern Recognition (SPR 2004), Lisbon, August 2004 http://www.esat.kuleuven.ac.be/~tdebie/papers/TDB-NC_04a.pdf
- 2 Jain, A.K., Murty M.N., and Flynn P.J. (1999): Data Clustering: A Review, ACM Computing Surveys, Vol 31, No. 3, 264-323. http://scgwiki.iam.unibe.ch:8080/SCG/uploads/596/p264-jain.pdf
- 3 J. Shi and J. Malik, "Normalized Cuts and Image Segmentation," IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2000. http://www.cs.berkeley.edu/~malik/papers/SM-ncut.pdf
- 4 Porter, M.F., 1980, An algorithm for suffix stripping, Program, 14(3) :130-137. It has since been reprinted in Sparck Jones, Karen, and Peter Willet, 1997, Readings in Information Retrieval, San Francisco: Morgan Kaufmann, ISBN 1-55860-454-4. Implementations: http://www.tartarus.org/~martin/PorterStemmer/
- 5 An implemenation of Spectral Clustering of 2D points: http://www.cs.utexas.edu/~surdules/Clustering/Clustering.html
Software
RSS Clustering Application
This is the primary piece of software for the final project. It is written in java and uses Jama for matrix operations.
[Source] [Java Web Start]
Kernel Classifying Simulation (for self education)
Out of curiousity, I wanted to see what some of the Kernel fittings look like in 2D space, so I put together this
quick visualization of the different kernels fitting points that have been classified into two regions.
[Souce] [Java Web Start]